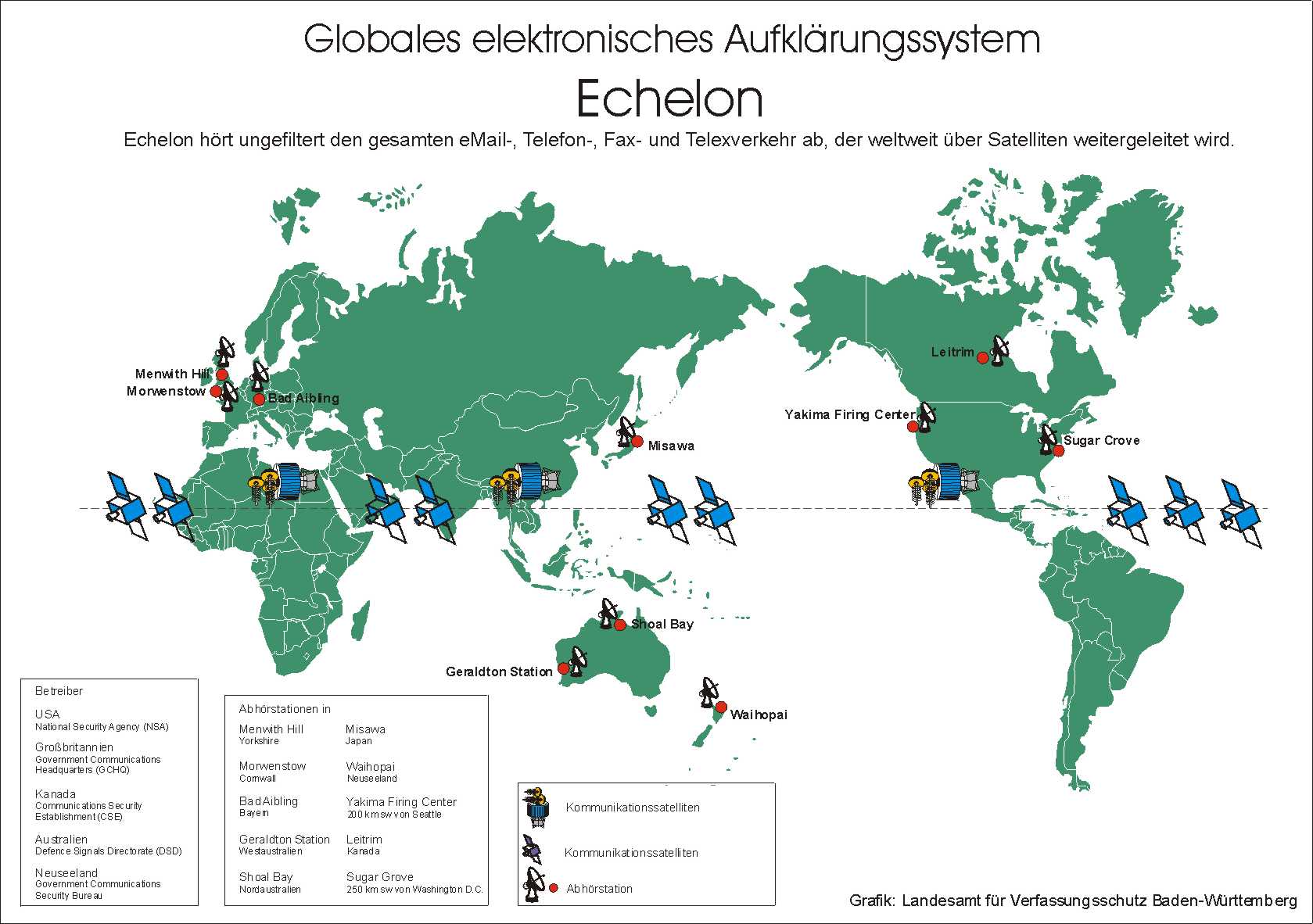
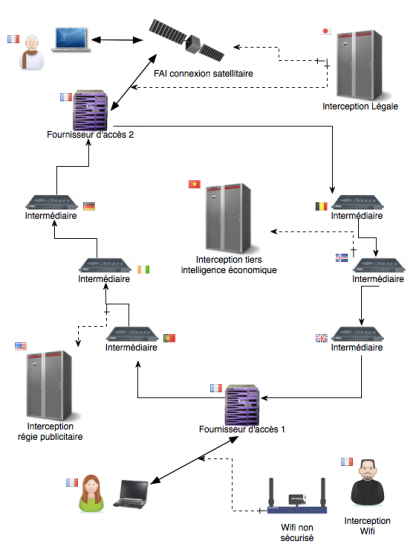
Une véritable catastrophe pour Internet semble être en route. Matignon aurait demandé à Arnaud Montebourg, Aurélie Filippetti et Fleur Pellerin d’étudier les modalités d’un rapprochement entre le CSA et l’ARCEP, et probablement l’HADOPI également même s’il n’en est pas encore explicitement fait mention. Dans son communiqué, le Premier Ministre s’exprime en ces termes :
Une véritable catastrophe pour Internet semble être en route. Matignon aurait demandé à Arnaud Montebourg, Aurélie Filippetti et Fleur Pellerin d’étudier les modalités d’un rapprochement entre le CSA et l’ARCEP, et probablement l’HADOPI également même s’il n’en est pas encore explicitement fait mention. Dans son communiqué, le Premier Ministre s’exprime en ces termes :
« Face à la convergence des infrastructures numériques, des services et des contenus qu’elles acheminent, des réseaux et des services fixes et mobiles, et des terminaux à l’usage du public, il est aujourd’hui essentiel de s’interroger sur l’efficacité des modes de régulation des communications électroniques et de l’audiovisuel, à l’heure où les contenus audiovisuels sont de plus en plus diffusés par l’internet fixe et mobile. En particulier, la diffusion des programmes audiovisuels acheminés par voie hertzienne est assortie d’une régulation des contenus destinée notamment à en assurer la qualité et la diversité, alors que les contenus diffusés via internet font l’objet d’une régulation plus limitée et parfois inadaptée« .
Internet, ce machin dont personne ne sait quoi faire
Ça ne fait jamais de mal de le répéter, Internet est un bien commun. En France cependant, aucun gouvernement n’a su lui attribuer la place qui lui convient. Internet a toujours été une dépendance plus ou moins directe du ministère des finances et du ministère de la culture. Internet, c’est une patate chaude. Reconnu par le conseil des sages comme un outil essentiel à l’exercice de la liberté d’expression. Aujourd’hui encore, le gouvernement au pouvoir ne voit en Internet qu’une sorte de vache à lait qu’il va bien falloir traire. Mais au lieu de traire la vache, ce dernier marque une obstination à traire le veau. Oui internaute, c’est bien de toi que je parle, c’est bien toi le veau… et on s’apprête à te traire. Pas financièrement, ça ce sera pour les Google, Youtube et autres gros consommateurs de bande passante. Du moins pas directement, car ça, c’est donner le feu vert aux FAI pour vous facturer l’utilisation de Google ou Youtube (en plus de celle d’Internet). Ne riez, pas ceci existe déjà dans les forfaits de téléphonie mobile. Mais il y a pire : c’est vos libertés que l’on va traire.
Les hautes autorités pseudos indépendantes
Commençons par les acteurs, ces « hautes autorités » vachement indépendantes et dépendant surtout des nomminations du président et de la majorité parlementaire en exercice. Pour le sujet qui nous anime aujourd’hui, elles ne sont pas deux, mais 4 (il y en a deux en embuscade) :
- L’ARCEP, nous le savons, c’est le « gendarme des telecoms » dont le rôle aujourd’hui c’est surtout de demander chaque année aux fournisseurs d’accès Internet et aux opérateurs telecom « Alors ton réseau cette année il marche bien ?« . Une fois que l’opérateur lui a répondu « oui, ça fonctionne au poil« , l’ARCEP consigne dans son rapport annuel « l’Internet en France est le meilleur du monde, notre ADSL fonctionne tellement bien que personne ne veut passer au très haut débit« .
- Le CSA (Conseil Supérieur de l’Audiovisuel) de son côté régule le « business des ressources rares ». Le CSA est en fait une sorte d’étiqueteur de rayon du supermarché des fréquences hertziennes, c’est tout de suite moins sexy que Conseil Supérieur de l’Audiovisuel, mais en pratique, son boulot, c’est étiqueteur.
- L’ANFR (l’Agence nationale des fréquences) : comme la technique et le CSA, ça fait 4, il faut bien une autorité qui sait de quoi elle cause. Une fois que le CSA a mis un prix sur une fréquence, techniquement, c’est l’ANFR qui les attribue et vérifie qu’on déborde pas sur les fréquences du voisin.
- L’HADOPI : celle ci je ne vous ferai pas l’affront de vous la présenter. Pour résumer, nous nous arrêterons sur la définition suivante : « la machine à spam la plus chère de l’histoire d’Internet ».
Chronologie d’une catastrophe annoncée
Ce rapprochement entre entités de régulation est malsain à bien des égards mais il n’est pas nouveau. Je vous en parlais dans ces pages en 2010, mais ça date en fait de fin 2006.
19 décembre 2006 : le rapport parlementaire Blessig ouvre les hostilités en préconisant un rapprochement entre régulateurs. Les concernés sont le CSA, L’ARCEP, et l’ANFR. Déjà en 2006 l’argument était d’amorcer le virage de la convergence entre Internet, téléphonie et télévision. On ne pouvait à l’époque lui prêter de mauvaises intentions.
Cette idée fut vite récupérée à d’autres fins que la simple convergence vers laquelle tout le monde s’accorde. L’un des plus fervents partisans de cette incongruité n’était autre que Frédéric Lefèbvre… en soi déjà, ça a de quoi foutre la trouille quand on se souvient de sa conception assez particulière d’Internet.
24 Novembre 2008 : Frédéric Lefèbvre présente un cavalier législatif (un article additionnel qui n’a rien à voir avec la choucroute) dans une loi sur l’audiovisuel public. Il vise à Introduire un peu de CSA dans Internet. Il défend son point de vue en arguant d’une nécessité de ce rapprochement pour la protection de l’enfance. Il le fit en en ces termes :
« Un nombre important de services de communication au public en ligne propose des contenus audiovisuels. Néanmoins, seuls les services de télévision et de radio ainsi que, grâce à la présente loi, les services de médias audiovisuels à la demande, offrent de réelles garanties en matière de protection de l’enfance et de respect de la dignité de la personne, grâce à la régulation du Conseil supérieur de l‘audiovisuel (CSA), qui dispose d’une vaste expérience dans ce domaine. »
« Il est donc proposé d’assurer, selon des modalités adaptées au monde de l’internet, la protection des mineurs par les autres services en ligne qui fournissent, dans un but commercial, des contenus audiovisuels à la demande. Cette protection doit être assurée notamment sur les sites de partages de vidéo dès lors que l’éditeur du service assure lui-même un agencement éditorial des contenus générés par les internautes. Ces modalités feront largement appel à l’auto-régulation. Le CSA pourra, après une large concertation avec les acteurs concernés, élaborer une charte de protection de l’enfance sur ces services et délivrer des labels à ceux d’entre eux qui la respecteront. Afin d’assurer l’efficacité de ce dispositif, il sera demandé que les logiciels de contrôle parental que les fournisseurs d’accès à internet doivent proposer à leurs abonnés, en application de la loi du 21 juin 2004 pour la confiance dans l’économie numérique, soient en mesure de reconnaître ces labels pour filtrer – si les parents le souhaitent – les sites qui n’en possèdent pas. »(…)
« Par ailleurs, il est proposé, par souci de cohérence et d’équité, que les services mentionnés ci-dessus, qui pourraient être définis comme des « services audiovisuels de partage et de complément », participent également au financement de la production d’œuvres cinématographiques et audiovisuelles dès lors qu’ils font concurrence aux autres services audiovisuels à la demande qui contribuent à ce financement. »
Décembre 2008 : Manque de bol, la protection de l’enfance n’avait su trouver une oreille assez attentive, le Frédéric passe donc la seconde… en fait non, il passe direct en cinquième avec nos fameux violeurs psychopathes nazis proxénètes qui planquent des médicaments contrefaits dans les armes (à cette époque Frédéric nourri des ambitions autres que celle de député par concours de circonstance). Il revient donc à la charge avec sa fameuse tirade :
« La mafia s’est toujours développée là ou l’État était absent ; de même, les trafiquants d’armes, de médicaments ou d’objets volés et les proxénètes ont trouvé refuge sur Internet, et les psychopathes, les violeurs, les racistes et les voleurs y ont fait leur nid » .
Et d’enfoncer le clou pour aller dans le sens d’une « régulation » :
« L’absence de régulation du Net provoque chaque jour des victimes ! Combien faudra-t-il de jeunes filles violées pour que les autorités réagissent ? Combien faudra-t-il de morts suite à l’absorption de faux médicaments ? Combien faudra-t-il d’adolescents manipulés ? Combien faudra-t-il de bombes artisanales explosant aux quatre coins du monde ? Combien faudra-t-il de créateurs ruinés par le pillage de leurs œuvres ? Il est temps, mes chers collègues, que se réunisse un G20 du Net qui décide de réguler ce mode de communication moderne envahi par toutes les mafias du monde ».
Le Frédéric, il avait bien envie de te le réguler ton Internet, de te le civiliser même. La mafia, les psychopathes, les violeurs, les pédophiles, les terroristes… si avec ça tu veux pas que je te régule, « comment comment veux-tu que je t’#@!%$ule ? ».
Mi-Janvier 2011 : Eric Besson reprend la patate chaude d’Internet de l’économie Numérique, un ex-secrétariat d’Etat noyé quelque part entre le ministère de la culture et Bercy. Il émet alors une fausse nouvelle idée en ajoutant une autre autorité, il s’agit maintenant de fusionner non pas deux mais 3 hautes autorités : l’ARCEP, le CSA et l’ANFR… comme en 2006. Sacré Éric, et avec ça il a voulu nous faire croire qu’il bossait. Bon ok, il a un peu plus bossé que NKM en demandant l’interdiction d’héberger Wikileaks en France (Eric Besson échoue avec un certain succès, puisqu’en 2012, la France a finit avec grand mal à dépasser la Roumanie en taux de pénétration du THD (très haut débit).
Avril 2012 : Michel Boyon, président du CSA, nous explique sa conception d’un Internet régulé à la sauce CSA, et il pue son Internet, il n’est pas que régulé, il est surtout fiscalisé. Il l’exprime en ces termes :
« on ne pourra pas indéfiniment faire coexister un secteur régulé, celui de l’audiovisuel, et un secteur non régulé, celui d’Internet »
Pour lui la convergence est un danger et seul le CSA pourra voler au secours des chaines de télévision car le développement des téléviseurs connectés, toujours selon ses propos, créent :
« une menace pour l’équilibre économique des chaînes ».
Une fois de plus, on sent bien qu’il n’est plus question de « régulation » mais de fiscalisation. Le CSA son truc à lui c’est les pépettes rien que les pépettes et tout pour les pépettes.
Ensuite, un ange passe, Internet fait la fête, François Hollande est élu, on se dit qu’HADOPI du Fouquet’s c’est bientôt terminé, que la Neutralité du Net sera bientôt inscrite dans la loi… bande de gros naifs.
Début juillet 2012 : Après la fête, la gueule de bois… Aurélie Filippetti sur RTL émettait l’idée d’une extension de redevance sur l’audiovisuel public aux écrans d’ordinateurs ! Taxer un support matériel d’accès indispensable à Internet au lieu de taxer les bidules box des FAI qui donnent accès à cet « audiovisuel public »… déjà, ça ne sentait pas bon du tout. Le projet se fait plus précis, le gouvernement veut taxer Internet, la convergence média n’est en fait qu’une convergence fiscale déguisée.
Mi-juillet 2012 : sur Reflets je tentais d’expliquer pourquoi un tel rapprochement était une erreur incommensurable guidée par un appétit fiscal au risque de dynamiter un bien et un intérêt commun. Au final, ni l’État, ni les entreprises qui pensent « être Internet », ni les internautes qui le sont vraiment (Internet), on t quelque chose à y gagner.
22 juillet 2012 : toujours sur Reflets, cette fois, c’est Fleur Pellerin qui annonce la mise à mort de la neutralité du Net, pour elle, ce machin est un concept bien américain fabriqué de toutes pièces pour favoriser les américains. Ça a mis du monde en colère chez nous, Fabrice Epelboin en tête.
Un rapprochement qui s’appuie sur deux erreurs techniques
L’argument principal d’un tel rapprochement, c’est ce qu’on appelle la convergence. Entendez convergence du média des médias Internet avec les média télévision, radio ou tout ce qui peut être allègrement taxé usuellement mais que l’on a beaucoup de mal à taxer sur Internet.
Internet ne converge pas, il est, avec sa neutralité, la condition indispensable à toute convergence.
La première erreur, c’est la définition que l’on pose sur le terme « convergence » appliqué à Internet. Ce que l’on appelle convergence chez quelques technocrates, les techniciens eux, appellent ça une absorption. Le terme est d’ailleur mal choisi, mais Internet est devenu la glue, le réceptacle de ces médias. Il offre des ressources non rares, ces mêmes ressources autrefois rares, qui en d’autres temps, justifiaient l’existence d’une autorité comme le CSA. Il faut bien comprendre que les ressources rares sur Internet, comme l’attribution d’une fréquence hertzienne, ça n’existe pas… Sur Internet, les ressources rares, ce sont des noms de domaines et des blocs IP comme je l’expliquais ici. Mais là encore, ce n’est surement pas au CSA de les gérer, c’est des jouets pour les grands ça, pas pour un étiqueteur de supermarché. Les ressources rares d’Internet ont un truc bien à elles qui est génial : quand il n’y en a plus et bien il y en a encore.
La seconde erreur (en rapport avec la première à cause des ressources rares) c’est une incompréhension technique de ce qui rentre et qui sort d’un tuyau et qui tient en deux notions : le broadcast et le multicast.
Le broadcast, c’est comme ça qu’un fourniseur d’accès à Internet vous vend de la VOD ou vous propose 4 fluxs HD simultannés. Le FAI émet, l’internaute reçoit, point final. Le FAI appelle ça pudiquement un service géré, un internaute averti appellera ça du minitel en 16 millions de couleurs.
Le multicast, c’est un peu plus fin, c’est la définition même d’Internet, dans lequel chaque Internaute peut recevoir ce qu’il demande à Google, Bing, Yahoo, Bittorrent ou Usenet ce qu’il SOUHAITE et non ce que son FAI lui PROPOSE DE CONSOMMER MOYENNANT FINANCES. Seconde subtilité, notre internaute qui fait de l’IP multicast comme monsieur Jourdain fait de la prose, il peut aussi et surtout émettre des données. Et oui, ça complexifie la donne de la régulation de comprendre qu’il y a en Internet le moyen de broadcaster en basant sur un réseau par définition multicast. Il y a aussi une difficulté à comprendre qu’en IP, sur notre Internet « moderne », le broadcast dépend du multicast.
Notre nouvelle autorité aura donc pour rôle de réguler quoi au juste s’il n’y a pas de ressources rares à réguler ?
La réponse est dramatiquement simple : elle va réguler les contenus, les contenus que VOUS produisez, que NOUS produisons. Cette autorité ne va pas réguler des entreprises qui seront autant de netgoinfres à l’affut du moindre brevet pour s’accaparer commercialement un bout d’Internet, cette autorité, elle va NOUS réguler.
Fiscalisation, protection de la propriété intellectuelle et protection de l’enfance sont les trois nouvelles mamelles de la surveillance du Net
La protection de l’enfance, c’est le cyber cheval de bataille du CSA. L’autorité est d’ailleurs parfaitement claire sur la question, elle s’est maintes fois prononcée pour une labellisation des sites web, et même, IMPOSER le FILTRAGE de sites non labellisés ! On voudrait tuer Internet en France qu’on ne pourrait pas mieux s’y prendre. Fusionner ARCEP, CSA, ANFR, HADOPI, et pourquoi pas la SPA ? (Internet est plein de zoophiles!).
Ramener Internet, un bien commun, sur lequel nul gouvernement, nulle entreprise n’a de droit de cuissage, à un nouvel eldorado fiscal, est probablement la plus belle escroquerie intellectuelle que les politiques peuvent jouer aux internautes.
Il ne viendrait pas à l’idée du gouvernement de créer une haute autorité de régulation de l’air que nous respirons, c’est pourtant bien ce qu’il s’apprête à faire avec Internet. La première escarmouche gouvernementale sur le terrain fiscal, c’est ce qu’annonçait Aurelie Filippetti en voulant étendre la redevance sur l’audiovisuel public aux écrans d’ordinateurs. Il ne lui serait pas par exemple passé par la tête l’idée de renforcer la fiscalisation des biens culturels vendus par les fournisseurs d’accès Internet qui par ce biais menacent en permanence la notion de neutralité du Net, une notion qui est un dû aux internautes et non une option comme certains aiment à tenter de nous le faire gober… oui Orange, c’est bien de toi que je parle.
Une autorité de régulation des médias sur Internet, c’est un peu comme si on créait une autorité de régulation de la presse. Quel rôle positif pourrait jouer une telle autorité ? Aucun. Son rôle est exclusivement fiscal. Cette fiscalisation va permettre la petite mort en France de la Neutralité du Net. Les industriels n’auront plus qu’à se partager le gâteau sous la bienveillante connivance de cette nouvelle super hyper giga haute autorité pseudo indépendante.
– « Et alors ? Ça va me coûter combien mon truc gratuit ? »
– « Oh trois fois rien, juste ta liberté d’expression »
Fiscal ? Vous avez dit juste fiscal ? Oui… enfin… pour le moment. Vous vous doutez bien qu’en embuscade se cache l’HADOPI et surtout, les moines copistes de DVD et tous les adorateurs de saint-copyright. Concentrer tous les pouvoirs dans une seule autorité pseudo indépendante qui mettra le paquet sur la chasse aux téléchargeurs de MP3 ? « Jamais » vous dira un gouvernement socialiste (quoi que)… mais que se passera t-il au prochain changement de majorité ? Et bien le gouvernement socialiste aura créé malgré lui (ou pas) un splendide outil de surveillance et de censure d’Internet dont il remettra les clés à ces moines copistes de DVD.
Ce genre de rapprochement, c’est une idée vraiment lumineuse, surtout quand on sait comment sont constitués nommés les collèges de ces autorités.

 On se doutait bien que le chateau de sable de l’ami Kim allait vite s’effondrer. Le marketing sur la crypto, c’est bien, l’implémentation correcte de mécanismes de chiffrement c’est mieux. J’avais, aux côtés de certains autres sceptiques, déjà émis les plus grandes reserves concernant l’utilisation de ce service en tentant de vous expliquer que la sécurité de Mega était bancale.
On se doutait bien que le chateau de sable de l’ami Kim allait vite s’effondrer. Le marketing sur la crypto, c’est bien, l’implémentation correcte de mécanismes de chiffrement c’est mieux. J’avais, aux côtés de certains autres sceptiques, déjà émis les plus grandes reserves concernant l’utilisation de ce service en tentant de vous expliquer que la sécurité de Mega était bancale.