C’était l’information à la con de la semaine, j’hésitais un peu à en causer tellement c’est pitoyable. Google a finit par débloquer une enveloppe de 60 millions d’euros à la presse française. Un accord ridicule pour une problématique qui l’est tout autant mais qui épargnera un moment encore aux parlementaires des maux têtes. Quand on voit le niveau de compréhension d’Internet de certains d’entre eux, on se dit qu’au final, ce n’est probablement pas un mal. Je vais à tout hasard tenter de me lancer dans une explication un peu détaillée de ce à quoi nous échappons pour le moment.
C’était l’information à la con de la semaine, j’hésitais un peu à en causer tellement c’est pitoyable. Google a finit par débloquer une enveloppe de 60 millions d’euros à la presse française. Un accord ridicule pour une problématique qui l’est tout autant mais qui épargnera un moment encore aux parlementaires des maux têtes. Quand on voit le niveau de compréhension d’Internet de certains d’entre eux, on se dit qu’au final, ce n’est probablement pas un mal. Je vais à tout hasard tenter de me lancer dans une explication un peu détaillée de ce à quoi nous échappons pour le moment.
☠ Why Google is evil
Google est connu comme étant LE moteur de recherche plébiscité par une immense majorité d’internautes. Mais il est aussi à l’origine de dizaines de services en ligne et de quelques produits qui rythment le quotidien de millions de gens à travers le monde. Google est également le plus gros aspirateur à données personnelles du monde. Ce qui a permis à Google de tant prospérer, c’est Internet. Et Internet, on ne le répètera jamais assez, vous allez voir que ce détail à son importance pour ce qui va suivre, c’est une machine à copier de l’information. Chaque mot que vous lisez actuellement se copie de routeurs en routeurs, de serveurs en serveurs, pour finir copié quelque part sur votre disque dur, à minima, dans un cache obscur.
Internet, en plus d’être une machine à copier des informations, est un réseau public. La notion de réseau public est quelque chose qui échappe pas mal à la presse.
Ce qui a fait le succès de Google, c’est qu’il a utilisé Internet en lui demandant de faire ce qu’il sait faire de mieux, copier des informations pour les rendre plus facilement accessibles, plus facilement copiables par d’autres. Google, à grand renfort d’algorithmes a ensuite hiérarchisé les informations qu’il avait copié.
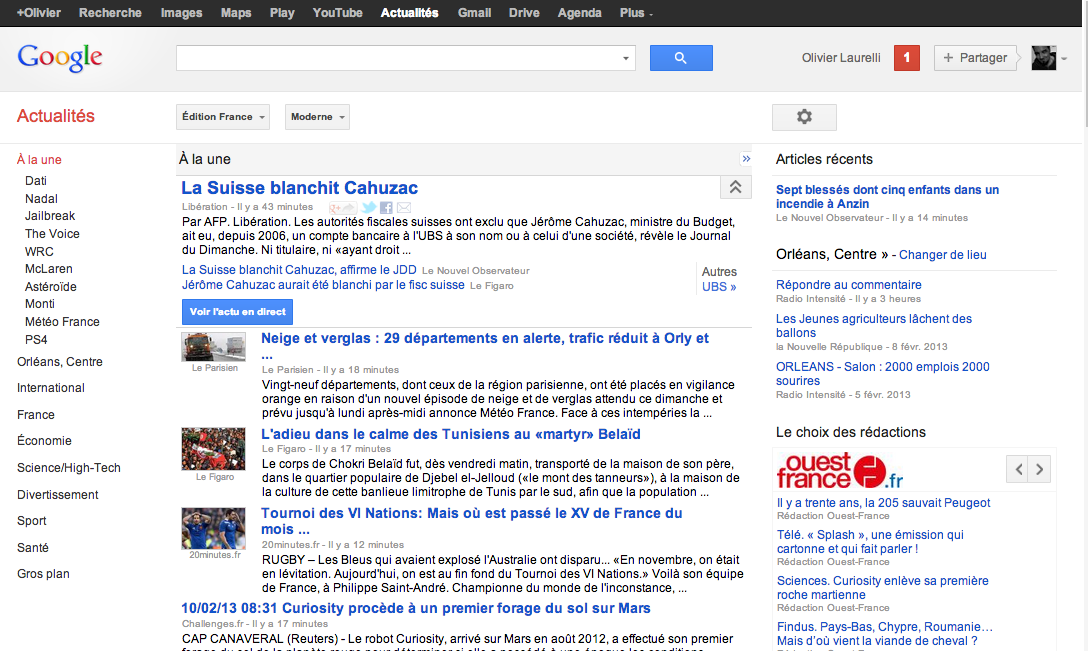
Il faut bien comprendre ce que la presse reproche à Google, le comble du ridicule étant de stigmatiser Google qui affiche dans sesrésultats de recherche les titres des actualités, éventuellement une photo en illustration et les quelques mots du début de l’actualité. Les éditeurs de presse y voient un vol, un transfert manifeste de valeur et une atteinte au droit d’auteur. Une page de résultats de recherche affichant un titre et quelques mots, c’est insupportable à leurs yeux.
Google est aussi montré du doigt pour sa position hégémonique.
☠ L’erreur de la valeur
C’est quelque chose que je répète assez souvent, mais visiblement pas suffisamment. Internet étant une machine à copier, doublée d’un réseau public d’échange (sous-pesez bien ces mots avant de lire la suite), il faut comprendre que ce sont les internautes qui tolèrent les « commerçants » sur Internet, pas le contraire.
- La valeur d’un réseau se définit très bien par la loi de Metcalfe qui énonce « L’utilité d’un réseau est proportionnelle au carré du nombre de ses utilisateurs« .
- La valeur d’une information peut en toute logique se calculer en fonction du nombre de noeuds du réseau Internet sur lesquels elle aura été répliquée… copiée.
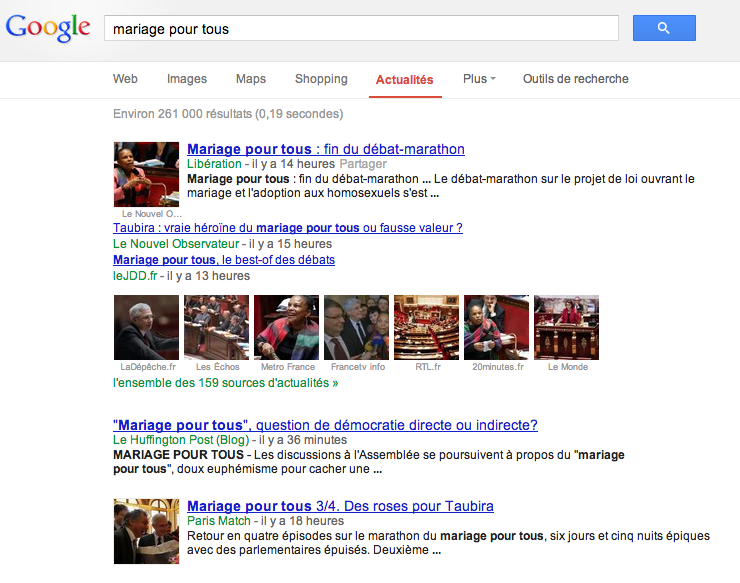
Nous venons de voir ensemble qu’une page de resultats de recherche Google contient le titre d’une information, quelques mots d’introduction et quand l’information apparait dans gooogle actu, la première affiche même une image. Ça ressemble à ceci :
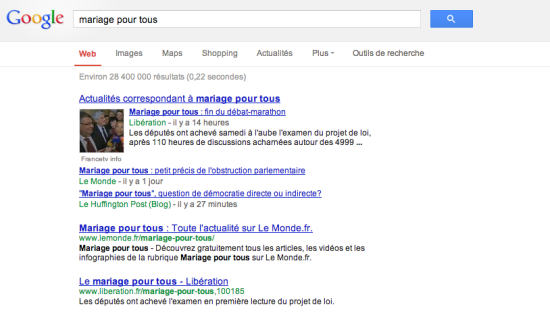
L’ordre sous lequel ces pages apparaissent, c’est la recette interne de Google, autre fois appelé pagerank, aujourd’hui Panda, il s’agit d’une suite d’algorithmes prenant en comptes de nombreux paramètres qui ont pour fonction de déterminer une pertinence d’affichage des résultats. Fréquentation, nombre de liens pointant vers la page ou le site en question, âge et fréquence des mises à jour du site (…)
Si ces algorithmes ne sont pas publics -et on comprendra pourquoi- ces derniers évoluent régulièrement et ont pour objectifs d’assurer une certaines « neutralité »… et non je sais un algo n’est jamais « neutre ». Mais au moins, la règle est la même pour tous.
La dernière grosse évolution, le passage à Panda, a été quelque chose de « dramatique » pour de nombreux sites marchands. Là où ils apparaissaient en première page sur certains mots clés, ils se sont vu relégués en 4e ou en 10e page sur les mêmes mots ou produits. Là on comprend bien la problématique de la valeur d’un référencement Google puisqu’elle impacte directement le portefeuille des commerçants. Google a sacrifié la rentabilité de certains au profit des internautes, pour leur offrir des résultats de recherche plus pertinents. Les marchands ont beau gueuler, on s’en fout, Google est chez lui, il fait ce qu’il veut, aux marchands de ne pas concentrer l’intégralité de leur CA sur ce moteur de recherche.
Commençons par une lapalissade : plus les actualités ou les pages de votre site apparaissent dans les premières positions, plus votre site a des chances d’être visité.
C’est là que nous abordons les arguments fallacieux des éditeurs de presse. Selon eux, et ça les agace particulièrement sur Google News… Il y aurait un « transfert de valeur ». :
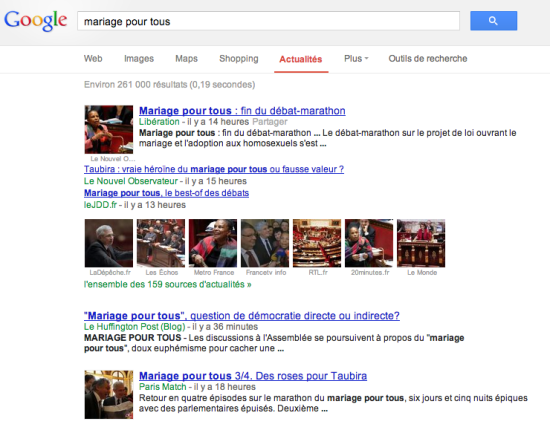
Google News est un agrégateur de titres d’informations, il affiche un titre avec le lien vers la news, quelques photos, et toujours notre description. La différence avec Google Search la plus évidente, c’est les algorithmes qui accordent une importance plus grande à la fraicheur de l’information.
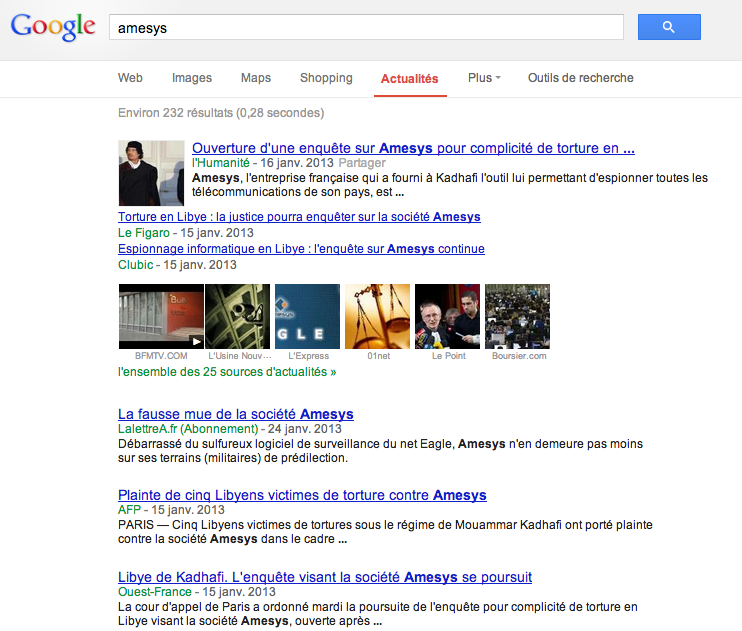
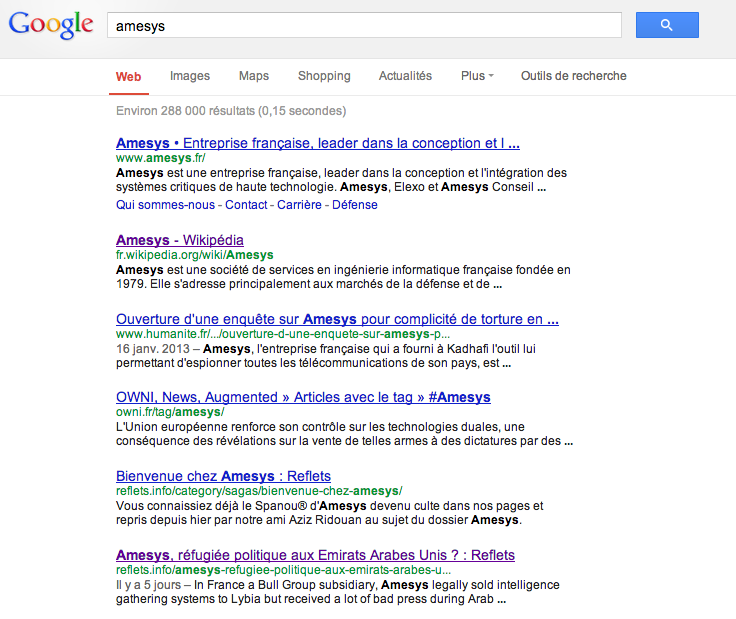
L’autre différence notable, et ça nous allons y revenir, c’est que tous les sites n’apparaissent pas dans Google News. Par exemple, si vous connaissez nos travaux sur Reflets à propos d’Amesys, vous vous dites que Reflets devrait très naturellement apparaitre dans Google News. Et bien non, ce n’est pas le cas. Reflets a beau être un média très lu, avoir le dossier le plus complet sur Amesys, être à l’origine des révélations sur la vente par cette société d’un système d’écoute global taillé sur mesure pour Kadhafi… Reflets n’apparait pas dans Google News. Il est en revanche en bonne position dans Google Search.
Voici pour Google News
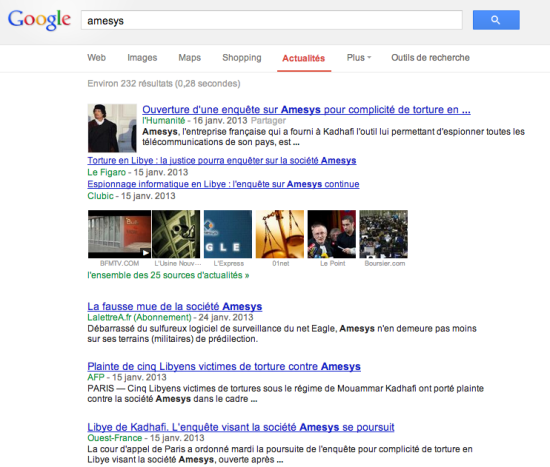
Et voici pour Google Search
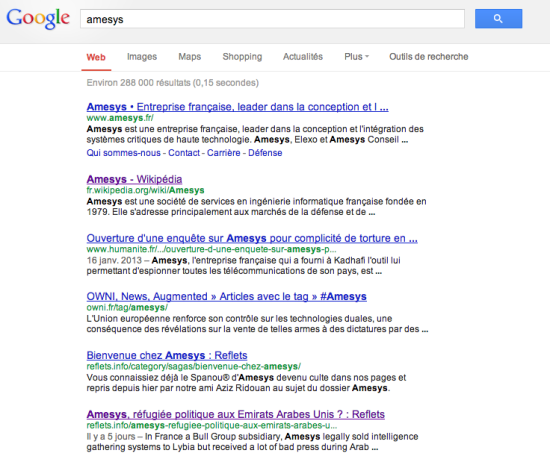
Conclusion 1 : Google choisi lui même (sur quel critère ?) qui va apparaitre dans Google News. Et donc qui est éligible à une part de la cagnotte de 60 millions ?
Conclusion 2 : le transfert de valeur dont les éditeurs de presse parle, Reflets en est victime puisque Google ne daigne pas afficher les articles de Reflets dans Google News alors que la presse elle même se goinfre régulièrement de nos actualités ou de nos infographies sans même prendre soin de nous citer.
Question : Faut sucer qui pour apparaitre dans Google News ?
C’est cette même presse qui accuse donc Google, via ses pages de résultats de recherche de lui « voler de la valeur ». Et là… désolé mais je me marre car si la presse se sentait si lésée que ça, elle mettrait en place un robots.txt pour interdir les bots de Google qui indexent son contenu. La presse veut le beurre, l’argent du beurre, et le cul de la crémière. En d’autres termes, elle veut
- Etre visible pour être visitée et donc générer des revenus publicitaires,
- Etre rémunérée pour avoir mis sur un réseau public de partage une information accessible au public (SIC!). En fait, c’est un peu comme si le gratuit Métro déposait des exemplaires de son gratuit dans les transports en commun et demandait à la SNCF ou la RATP de passer à la caisse !
Déjà, vu d’ici, ça sent le foutage de gueule…
Google est le site qui draine le plus de trafic, même si ceci est de moins en moins vrai et ça aussi nous allons y revenir pour que vous preniez conscience de l’hypocrisie de ces gens là.
Google n’est pas qu’un agrégateur d’information ou un moteur de recherche, il est aussi et surtout, c’est son fond de commerce, la plus grande régie publicitaire du monde. Et c’est à ce titre que nos amis de la presse d’en haut pourraient justifier d’un transfert de valeur. Car dans leur tête, les lecteurs sont tellement cons, qu’ils s’arrêtent à la lecture du titre et de la description affichée sur Google News. Faut dire que le lecteur il en a un peu raz la casquette de lire des dépêches AFP remixées… mais non, le coupable pour elle, c’est Google.
En « captant » les lecteurs dans ses résultats de recherche, la presse affirme donc que Google s’octroie des revenus publicitaires qui lui sont destinés… OH WAIT ! Il n’y a PAS DE PUB sur les pages de résultats de Google News !!
Mais alors ? S’il n’y a pas de publicité sur les pages de Google News, comment peut-on affirmer que Google « vol » des revenus publicitaires à la presse alors que Google facilite l’accès aux dépèches AFP remixées de cette même presse pour qu’elle puisse se goinfrer avec sa régie publicitaire qui dans bien des cas est … Google. Et voilà la boucle bouclée.
Conclusion : Tranfert de valeur… MON CUL !
☠ Des cacahuètes pour calmer la presse française
L’affaire était tellement sérieuse que la présidence de la République elle même est intervenue pour négocier avec Google un sachet de cacahuètes (une enveloppe de 60 millions d’euros sur 3 ans), histoire de calmer la presse d’en haut. C’était ça ou une loi. Une loi Google… Une loi qui aurait été un naufrage parlementaire, une loi qui aurait porté un grave coup à Internet, cette machine à copier, ce réseau d’échange ouvert.
Car après Google Facebook, après Facebook, Twitter, puis comme le réseau social chinois QQ Zone ne paye pas, on aurait, pourquoi pas… décidé de bloquer les informations de la presse française sur la Chine… tant et si bien qu’Internet ne serait plus Internet mais un ensemble de réseaux locaux régis par des accords commerciaux entre réseaux sociaux friands de partage d’information et sites de presse. Le FFAP donne le ton, toujours en arguant d’un transfert de valeur (WTF?!), et vous verrez que ce n’est que le début… une bande de vautours décomplexés.
☠ Et si la presse rémunérait sa vraie source de valeur… comme Google le fait pour elle ?
Google n’est pas le seul à générer du trafic. Les internautes qui partagent des informations sur Facebook et sur Twitter … voilà l’origine première de la valeur des sites des presse aujourd’hui, car ce sont eux qui permettent à la presse d’accroitre le plus considérablement leurs revenus publicitaires. Est-ce pour autant que la presse va décider de reverser une partie de ses revenu publicitaires aux internautes qui partagent le plus leur information ? Ceci serait pourtant légitime…
L’enveloppe de 60 millions, c’est un moindre mal. C’est une fleur de Google, rien ne l’y obligeait, et si l’affaire était portée devant les tribunaux, je ne donne personnellement pas cher de la presse française. D’autres pays européens vont suivre et malheureusement, une loi c’est bien ce qui nous pend au nez. Et une loi, ce sera forcement une tragédie pour Internet.
Et quand loi il y aura, Google sera en véritable position de force, car il pourra, comme il l’avait fait en Belgique, déréférencer les sites de presse de Google News et peut peut-être référencer des sites comme Reflets.info qui ne lui demandent rien et qui ne passent pas leur temps à remixer des dépêches AFP.
Là où ça sera plus coton, ça va être pour des sites comme Facebook qui regorgent de pub. Oui sur Facebook, la presse a un coup à jouer, c’est même surprenant qu’elle s’en prenne à Google et non aux utilisateurs de Facebook ou de Twitter qui comme Google, contribuent à sa valeur… mais eux, avec de la pub, donc un pseudo transfert de valeur.