
Oui, ça devient fatigant d’avoir à ré-expliquer 50 fois les mêmes choses…
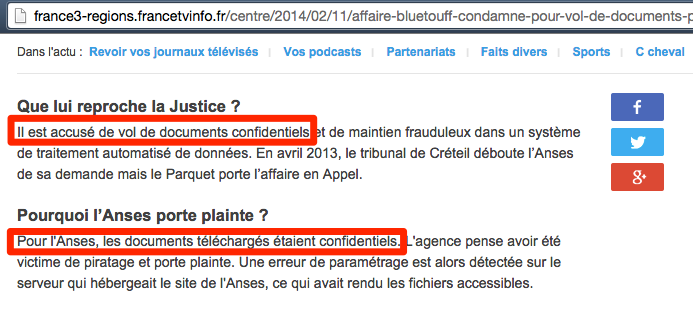
Non, les documents de l’ANSES n’étaient pas confidentiels .. ceci est consigné dans les PV, l’ANSES n’était même pas partie civile en première instance ! Ces documents n’avaient rien de confidentiels. L’ANSES a bien cru à un piratage, mais après vérification, elle a parfaitement compris qu’il n’y avait ni piratage ni documents « confidentiels ». Il s’agissait d’études, pleines de chiffres pour la plupart, difficilement interprétable pour des non chercheurs.

Et bien non et encore non… je ne suis pas arrivé au « coeur de l’extranet », d’ailleurs c’est quoi le coeur de l’extranet ? Pour moi le coeur de l’extranet ça aurait été la base de données, contenant mots de passes et toutes les données … mais voilà, ce n’est pas ce que je cherchais, et heureusement car j’aurais par exemple pu tomber au piff sur un répertoire /backups avec des données peut-être autrement plus sensibles…
Je suis arrivé dans un répertoire nommé xxxx/DOCS ne contenant NI DONNEES PERSONNELLES, NI FICHIERS SYSTEMES pouvant me laisser penser que je me trouvais dans un espace « sensible »… ce n’est pas comme si je m’étais trouvé par exemple ici (oui ils sont prévenus depuis plusieurs semaines, voir mois, mais je pense qu’ils s’en foutent, et puis un jour on met des documents « confidentiels » qui se retrouvent indexés par Google hein…)
Je n’étais pas dans /DOCSCONFIDENTIELS
non… juste /DOCS
… Sans aucune indication sur le caractère privé ou confidentiel de ce répertoire.
Et depuis quand le fait d’arriver sur une page d’accueil avec un champs d’identifiant et de mot de passe a une influence automatique et absolue sur les permissions de tous les sous-répertoires ?
Je n’ai pas su expliquer au juge la différence entre authentification et permissions des sous-répertoires, il faut dire qu’ayant déjà du mal à prononcer correctement Google, tenter une explication était de toutes façons voué à l’échec… ou peut-être n’a t-il tout simplement pas voulu entendre que s’il y a bien un champs d’identifiant et de mot de passe sur Facebook et Twitter par exemple, ceci ne veut pas dire que tout ce qu’il y a sur ce site est privé ou confidentiel.
Mais là où cet article de France 3 va encore plus loin que le juge, c’est quand il affirme
Le fait d’avoir téléchargé les 8000 documents ne plaide pas en sa faveur car cela tend à prouver qu’il craignait de ne pas pouvoir accéder à nouveau à ces documents.
C’est quelque chose que j’ai maintes fois expliqué, si j’ai téléchargé ces documents, c’est pour pouvoir chercher dans leur contenu en utilisant l’indexation de ma machine.
Oui dans la tête d’un juriste qui ne sait pas ce qu’est une authentification et une permission, c’est « normal » de me condamner, oui dans la tête d’une personne qui préfère ouvrir un par un des documents pour chercher des mots dedans au lieu de lancer un cat *.doc |grep foo c’est normal de me condamner… Et après ? Et après j’ai envie de mettre ça sur le compte de l’e-gnorance, mais même ça j’ai un peu de mal.